cGAN : How to Boss Around Your AI
The Problem with Vanilla GANs
So, you built a GAN (from my previous post). It generates handwritten digits. Cool!
But here's the catch: You ask it for a number, and it gives you a random 7. You ask again, it gives you a 3. You scream "GIVE ME A 9!", and it calmly hands you a 1.
Vanilla GANs are like a talented but chaotic artist. They can draw, but they don't take requests.

Enter cGANs (Conditional Generative Adversarial Networks).
What is a cGAN?
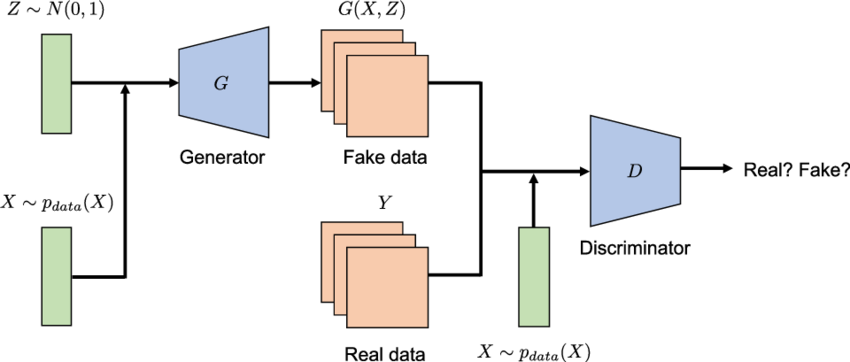
A Conditional GAN is just a regular GAN that went to obedience school. Instead of just feeding random noise to the Generator, we feed it Noise + A Condition (like a class label).
And we don't just tell the Generator. We also tell the Discriminator: "Hey, check if this image is real AND if it matches this label."
The Analogy
- Vanilla GAN: You walk into a coffee shop and say "Give me a drink." You might get coffee, tea, or water. Who knows?
- cGAN: You walk in and say "Give me a Coffee." Now, if they give you tea, you know it's wrong, even if it's a perfectly good cup of tea.
The Architecture Change
It's actually a surprisingly simple tweak.
- Generator: Takes
Noise (z)+Label (y)Generates Image. - Discriminator: Takes
Image (x)+Label (y)Real or Fake?
The Math (Still Don't Panic)
Remember our Minimax game? We just add a little (the condition) to the probability terms.
Basically, everything is now "given ".
Code Example: The "Concatenation" Trick
In PyTorch, the easiest way to "feed" the label is to turn it into a vector (using an Embedding) and just glue it (concatenate) to the image or noise.
1. The Generator
We take the noise vector and the label vector, mash them together, and feed that into the network.
class Generator(nn.Module):
def __init__(self, z_dim, num_classes, img_dim):
super().__init__()
self.img_dim = img_dim
# Create an embedding for the label (e.g. digit 0-9)
self.label_embed = nn.Embedding(num_classes, 10) # Map label to vector of size 10
self.gen = nn.Sequential(
# Input size is Noise + Label Embedding
nn.Linear(z_dim + 10, 256),
nn.LeakyReLU(0.1),
nn.Linear(256, img_dim),
nn.Tanh(),
)
def forward(self, noise, labels):
# 1. Turn the label (e.g., "5") into a vector
label_vector = self.label_embed(labels)
# 2. Glue it to the noise
combined_input = torch.cat([noise, label_vector], dim=1)
# 3. Generate!
return self.gen(combined_input)
2. The Discriminator
The Discriminator needs to see the image AND the label to know if they match.
class Discriminator(nn.Module):
def __init__(self, img_dim, num_classes):
super().__init__()
self.label_embed = nn.Embedding(num_classes, 10)
self.disc = nn.Sequential(
# Input size is Image + Label Embedding
nn.Linear(img_dim + 10, 128),
nn.LeakyReLU(0.1),
nn.Linear(128, 1),
nn.Sigmoid(),
)
def forward(self, image, labels):
# 1. Turn label into vector
label_vector = self.label_embed(labels)
# 2. Glue it to the image
combined_input = torch.cat([image, label_vector], dim=1)
# 3. Judge it!
return self.disc(combined_input)
Why is this cool?
Because now you have Control.
In a vanilla GAN trained on faces, you just get "a face". In a cGAN, you could train it on attributes like "Glasses", "Blonde Hair", "Smiling".
Then you can literally type: generate(smiling=True, glasses=True) and boom.

Conclusion
cGANs are the bridge between "AI doing random cool stuff" and "AI doing what we actually want." It's a small math change, but a huge leap in usability.
Next up? Maybe we'll look at CycleGAN (turning horses into zebras). Stay tuned!