WGAN : Bringing Sanity to the GAN Chaos
The GAN Tantrum
If you've tried training a vanilla GAN, you've probably seen the loss graph look like a heart attack monitor before flatlining completely.
One minute, it's learning. The next, the Discriminator gets too good. It looks at the Generator's art, laughs, and says "FAKE" with 100% confidence.
When the Discriminator is perfect, the gradient is zero. The Generator gets no feedback. It's like trying to learn painting, but your teacher just screams "BAD!" without telling you why.

The Root Cause: Bad Metrics
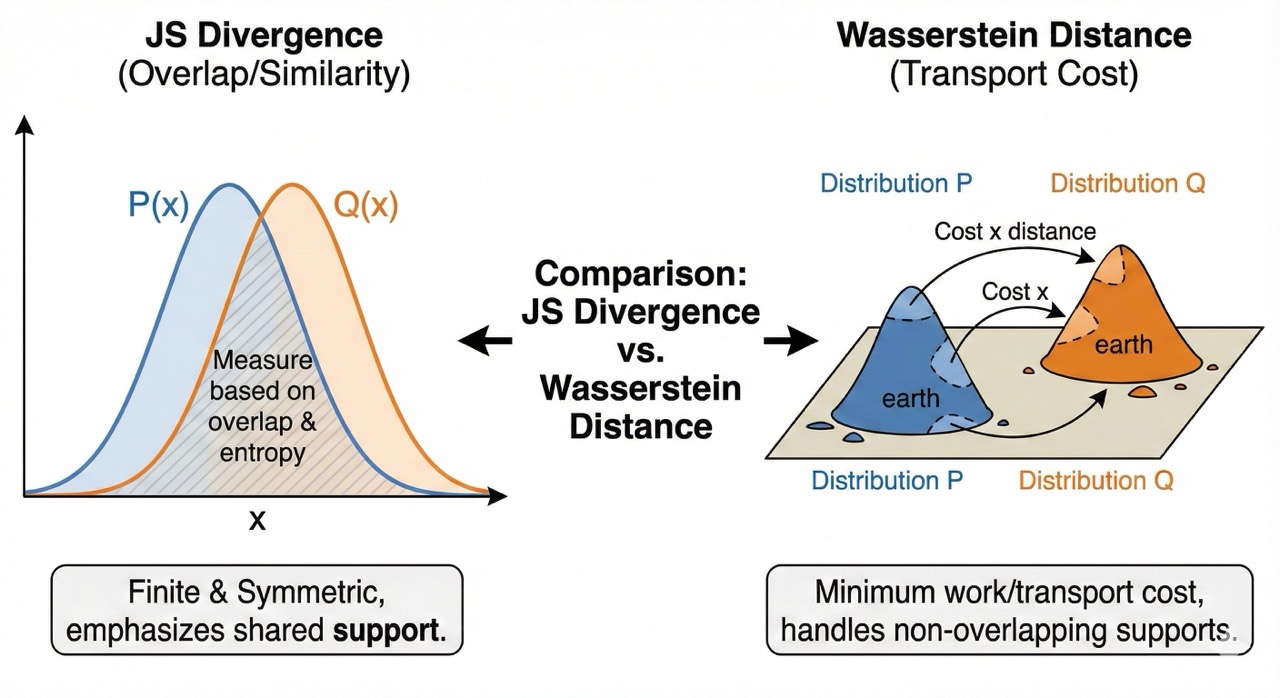
The problem lies in how we measure the difference between the Real distribution and the Fake distribution. Vanilla GANs use something called Jensen-Shannon (JS) Divergence.
Imagine two parallel lines. They never touch.
- What's the distance between them? 5 meters? 10 meters?
- JS Divergence looks at them and says: "They are different. That is all I know. Maximum difference."
It doesn't tell you how far they are, just that they are distinct. If the distributions don't overlap, the gradient vanishes.
Enter Wasserstein (The Earth Mover)
Wasserstein Distance (also called Earth Mover's Distance) changes the game.
Imagine the "Real" distribution is a pile of dirt in location A, and the "Fake" distribution is a pile of dirt in location B. The Wasserstein distance is: How much work does it take to move the dirt from B to A?
- If the piles are far apart, the cost is high.
- If they are close, the cost is low.
Crucially, even if they don't overlap, there is still a gradient. The Critic can say: "You're wrong, but if you move the pixels this way, you'll be less wrong."
The "Critic" vs The "Discriminator"
In WGAN, we don't call it a Discriminator anymore. We call it a Critic. Why? Because it doesn't classify (Real vs Fake). It gives a Score.
- Discriminator: "Probability this is real is 0.9." (Sigmoid output 0-1)
- Critic: "This image has a realness score of 5.2." (Linear output, can be anything)
The Implementation Checklist
To turn a GAN into a WGAN, you need to break a few rules:
- Kill the Sigmoid: Remove the last sigmoid layer from the Critic. We want raw scores, not probabilities.
- New Loss Function: No more logs.
- Critic Loss: (Maximize difference between real and fake scores)
- Generator Loss: (Maximize the fake score)
- Clip Weights: This is the "duct tape" part. To keep the math valid (1-Lipschitz continuity, don't ask), we force the Critic's weights to stay in a small box, like .

Code Example
Here is how simple the changes are in PyTorch.
1. The Critic (No Sigmoid!)
class Critic(nn.Module):
def __init__(self, img_dim):
super().__init__()
self.crit = nn.Sequential(
nn.Linear(img_dim, 128),
nn.LeakyReLU(0.1),
nn.Linear(128, 1),
# nn.Sigmoid() <-- DELETED! GONE!
)
def forward(self, x):
return self.crit(x)
2. The Training Loop (Weight Clipping)
# Hyperparameters
clip_value = 0.01
n_critic = 5 # Train critic 5 times for every 1 generator step
for epoch in range(num_epochs):
for _ in range(n_critic):
# ... load real images ...
# Train Critic
noise = torch.randn(batch_size, z_dim)
fake = gen(noise)
critic_real = crit(real).reshape(-1)
critic_fake = crit(fake).reshape(-1)
# Loss is just the difference (Maximize Real - Fake)
loss_critic = -(torch.mean(critic_real) - torch.mean(critic_fake))
crit.zero_grad()
loss_critic.backward(retain_graph=True)
opt_crit.step()
# CLIP WEIGHTS (The WGAN magic/hack)
for p in crit.parameters():
p.data.clamp_(-clip_value, clip_value)
# Train Generator (once every n_critic steps)
gen_fake = crit(gen(noise)).reshape(-1)
loss_gen = -torch.mean(gen_fake) # Try to get a high score
gen.zero_grad()
loss_gen.backward()
opt_gen.step()
Conclusion
WGANs are much more stable. You can actually watch the loss go down and mean something. The images improve smoothly instead of snapping into existence or collapsing into garbage.
Is it perfect? No. Weight clipping is kind of ugly (WGAN-GP fixes that, but that's a story for another day). But it's a huge step towards keeping your sanity intact.
